

激活函数的作用
激活函数的作用主要是增加神经网络的非线性。神经网络的每一层都有矩阵相乘,如果不使用激活函数,每一层的输出都是上层输入的线性函数,无论神经网络有多少层,输出都是线性组合,并没有办法解决非线性问题。所以必须引入非线性函数作为激活函数,这样深层神经网络就有意义了,并可以解决线性模型所不能解决的问题。
Sigmoid
公式定义:
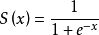
导数公式:
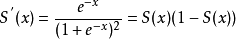
函数以及导数图像如下:
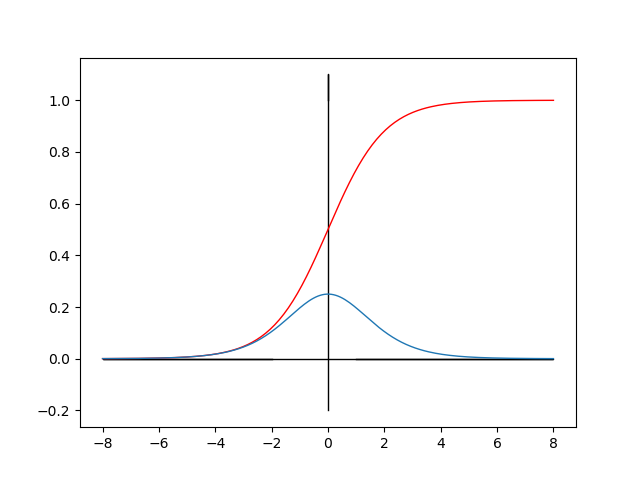
ps:红色为函数图像,蓝色为导数图像
可以看出Sigmoid的取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用于输入的归一化。同时,Sigmoid函数求导比较容易,可以直接推导得出。
但是,从导数图像可以看出,当x趋向于正无穷或者负无穷时,导数趋向于0。具有这种性质的称为软饱和激活函数。在反向传播的过程中,一旦输入落入饱和区,导数就会接近于0,导致向后面传递的梯度也会变得非常小。这样的话网络参数就会很难得到有效的训练。这种现象称之为梯度消失。
Tanh
公式定义:
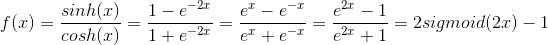
导数公式:
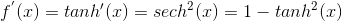
函数以及导数图像如下:

ps:红色为函数图像,蓝色为导数图像
可以看出,Tanh的输出是以0为中心的,所以收敛速度要比sigmoid快,减少了迭代次数。然而从导数图像可以看出,tanh一样具有软饱和性,从而使得梯度消失。
ReLU
ReLU函数又称为修正线性单元,是一种分段线性函数,弥补了sigmoid函数和tanh函数的梯度消失问题。
公式定义:
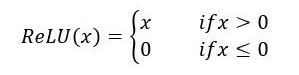
导数公式:

图像如下:

由上图可看出,ReLU函数是一个分段性函数,把所有负值都变为0,而正值不改变,这种操作称之为单侧抑制。这样就能使得神经网络中的神经元具有了稀疏激活性,防止过度拟合。而且ReLU函数的非负区间的梯度为常数,因此不会存在梯度消失的问题,使得模型的收敛速度维持在一个稳定状态。在使用RuLU函数时,learning rate不能设置很大,否则很有可能使得你网络中的40%的神经元坏死。所以在使用Ru LU函数时,尽量选择一个合适的较小的learning rate。
Leaky ReLU
Leaky ReLU函数又称为PReLU函数,是通过ReLU改进的函数。公式定义如下:

其中a的取值为(0,1)之间。
导数公式:

图像如下:

Leaky ReLU函数解决了ReLU函数在输入为负的情况下产生的梯度消失问题。
Softmax
Softmax函数又称归一化指数函数,用于多分类神经网络输出。其公式定义如下:

Sigmoid就是类别为2的Softmax。相对于Sigmoid来说,Softmax的结果之和一定唯一并且定义域为一个一维向量。如:
1 | test = [8.2, 6.8, 0.7, 1.5] |
输出:

ps:8.0103743e-01为8.0103743乘以0.1,其他三个类似。
如何选择激活函数
通常来说,不能把各种激活函数串起来在一个网络中使用。如果使用ReLU,那么一定要小心设置学习率,防止网络中出现过多的死亡神经元。如果神经元死亡过多这个解决不了,可以试试Leaky ReLU。尽量不要使用Sigmoid激活函数,目前主流一般都是使用ReLU激活函数。如何搭建一个多分类的神经元,在最终输出使用Softmax激活函数。
